
Paradoxical Truth: The more human a community becomes, the more machine-valuable it is. What makes Reddit chaotic, emotional, and creative is precisely what makes it indispensable for training better AI models.
Preliminary Issues
Before I dig into my mostly qualitative argument for RDDT, let’s dig into a few issues that have been hammering the stock recently.
The elephant in the room is this “ChatGPT Citations by Domain” chart:
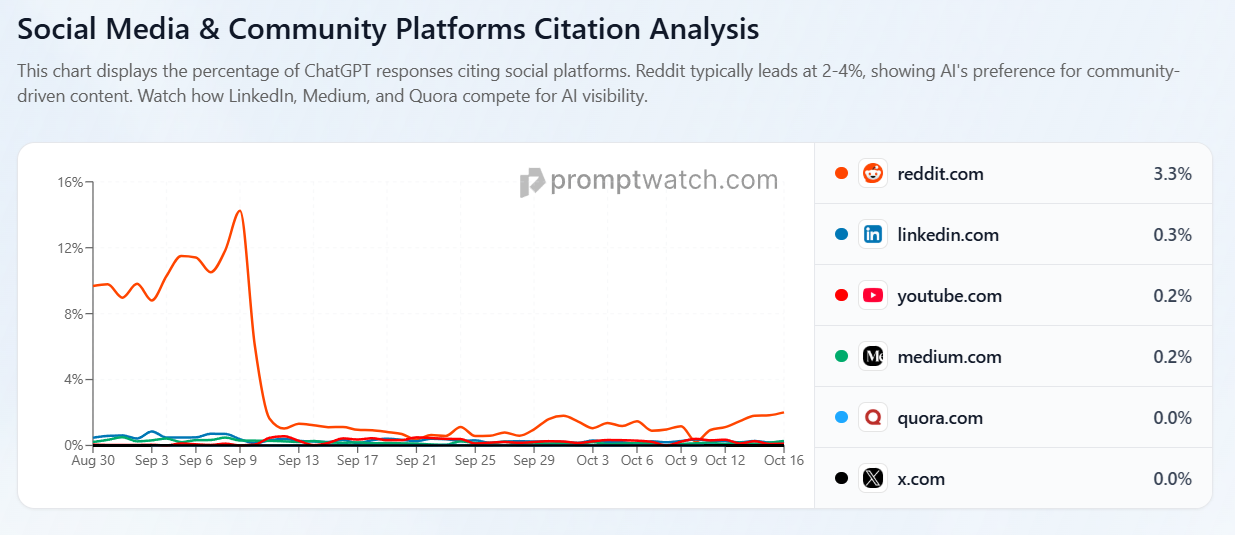
The release of the September numbers showed a major decline in the percentage of ChatGPT responses citing Reddit, sending RDDT down 25% from a high of $270.
The market has incorrectly digested this new datapoint. Of course, OpenAI and every single LLM vendor will suppress external links away from their platform over time – this is their default behavior given their incentives to monetize on their own platforms.
What this does not show – and I suspect OpenAI or any LLM vendor will never show – is the increasing amount of data that these LLMs are using from Reddit for training.
The pullback is an irrational, knee-jerk reaction and I believe it will be corrected shortly.
Let’s now review the ARPU (avg. revenue per user) and DAU (daily active users) for Reddit compared to Facebook from- the largest social media platform.
Reddit vs. Facebook Q2 2025 ARPU, Global and U.S.
| Platform | Global ARPU | Global YoY | U.S. ARPU | U.S. YoY |
| $4.53 | +47% | $7.87 | +59% | |
| $13.65 | +15% | $18.00 | +10% |
Reddit vs. Facebook Q2 2025 DAU, Global and U.S.
| Platform | Global DAU | Global YoY | U.S. DAU | U.S. YoY |
| 110.4 million | +21% | 50 million | +18% | |
| 2.15 billion | +3% | 200 million | +1.5% |
On the surface, it appears that Reddit is marginally profitable compared to Facebook – that it is unable to monetize its content. That’s a surface-level reading.
What I see from the numbers is a platform that is growing exponentially faster than Facebook in terms of DAU while still being able to generate a healthy ARPU (33% and 44% of Facebook on global and U.S. basis).
Being an active Reddit user myself, and having been on Facebook since its early days (2009), I can anecdotally share that my network that are still active on my Facebook are definitely not sharing the type of content that keeps me coming back to Reddit. The DAU and ARPU mask the huge potential of unlocking valuable demographics (e.g., middle to upper-middle class millennials in their peak earning years).
Landscape of Thought
If you’re mathematically inclined, LLMs’ reasoning and text generation can be viewed as tracing a geodesic – the locally optimal (low loss, high coherence) path – through its learned latent manifold of meaning. If you want to learn more.
It’s a lot of words for something that has a beautiful geometric representation.
Imagine you’re a lost hiker on mountain and you’re on a journey where the final destination is unknown. Your starting location – high on the mountain – is the input you feed into an LLM. The LLM itself is represented by your current map or understanding of the terrain.

At each step of inferencing, the LLM advances one waypoint along a geodesic – the locally most coherent, lowest-loss continuation of the path traced by the preceding context. A conversation you have with the LLM is represented by the series of geodesics you take along your journey.
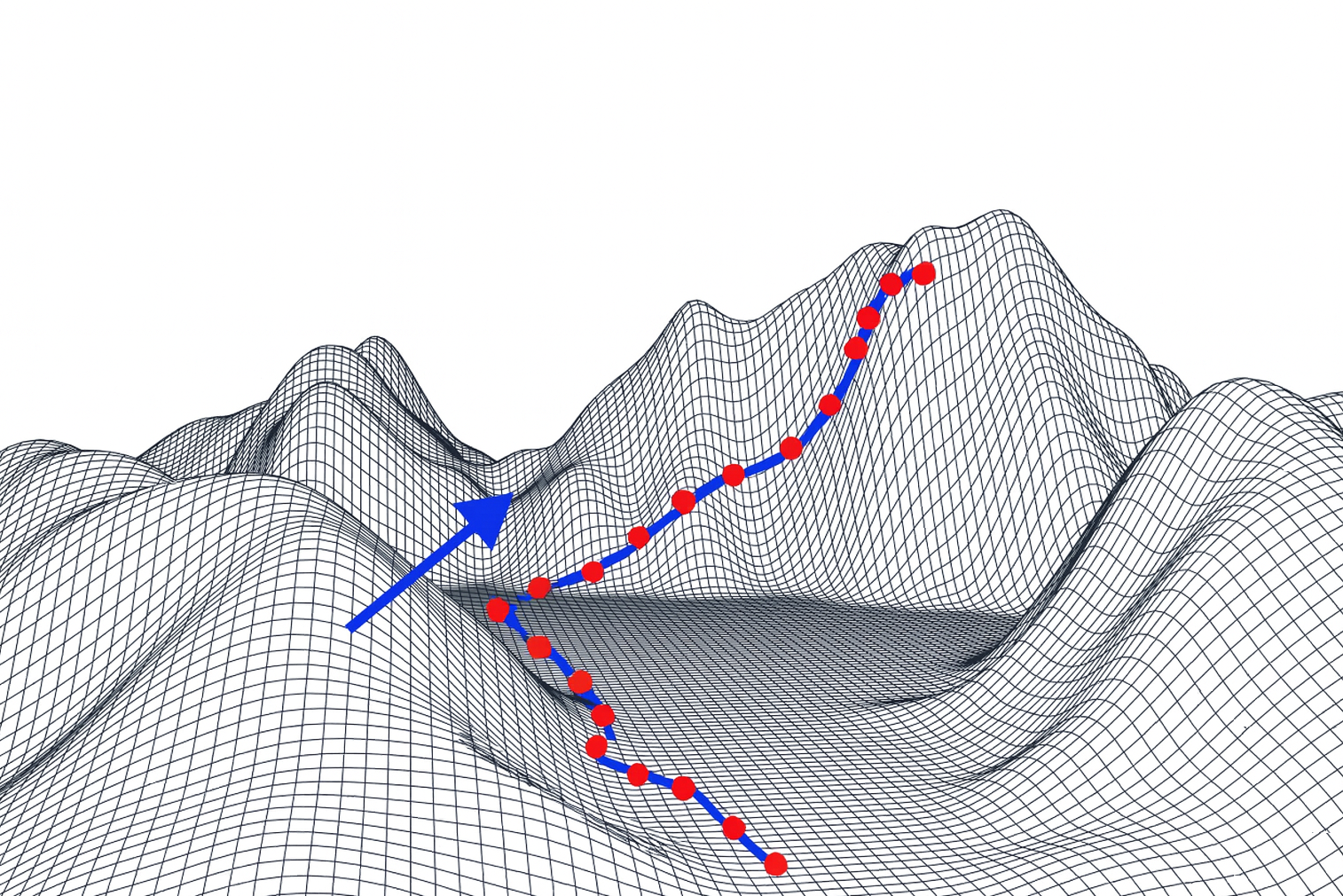
Now imagine there is a persistent fog that pervades this mountain. As the fog slowly dissipates, training is the process by which you acquire this newfound knowledge of the local terrain. Training data can come in three forms:
- Redundant data
- Mildly novel data
- Transformative data
Redundant data clears away fog in a well-known valley, providing sharper local details but no new connections. Mildly novel data clears away fog along foothills, extending known contours, but providing glimpses of new areas for discovery. Transformative data lifts the fog completely in the local terrain – revealing hidden paths and unseen peaks – and extending the global topology of your map.
Lifting the Fog of Social Media Data
From my perspective as a long-time user and content creator on platforms like Facebook, X/Twitter, and Reddit, here are my simple observations.
- Facebook represents redundant data. Most of the activity on Facebook is personal in nature – people sharing memories about friends and family, highlighting a trip they took abroad, maybe a promotion at work. The corpus is very limited in terms of new knowledge that LLMs don’t already know.
- X/Twitter represents mildly novel data. The platform’s popularity has become its Achilles heel. First, the emphasis on influencers (those with high follower counts) means that even creative and insightful tweets are not promoted by the algorithm. This leads to group think. Second, the number of bots is exorbitant and it appears Elon Musk has not solve this problem or actually doesn’t want it solved for certain reasons.
- Reddit represents transformative data. I have posted on multiple subreds spanning from investing (r/investing, r/stocks) to early retirement (r/fire, r/fatfire) to Christianity. First, even as someone who just joined the platform, the algorithm ranks your post based on the quality of it, not how many followers you have. In fact, one of the features that makes Reddit so great is there is no notion of follower count – there are no influencers.This leads to quality, creative and insightful ideas being created. Second, its a truly global platform where anyone no matter your social status and education can argue and debate and be ranked (“upvoted”) based on your quality of your ideas. Group think (although present somewhat in some subreds) is limited on the platform as whole. This leads to more uncorrelated data.
Let me share some examples. Here is a common type of post on Facebook where someone is asking for a new trial of a subscription service.

I don’t want to be blunt, but what value does this add to the LLM corpus (which includes all of the Internet and increasingly industry and subject matter experts)?
Very limited – it’s redundant data.
Moving on to Twitter/X, here is a common type of post by an influencer in finance named Bill Ackman, who runs a hedge fund. Bill is an influencer with 1.8 million followers, so he is often on the feed of folks in finance and those working at prominent/prestigious corporates.
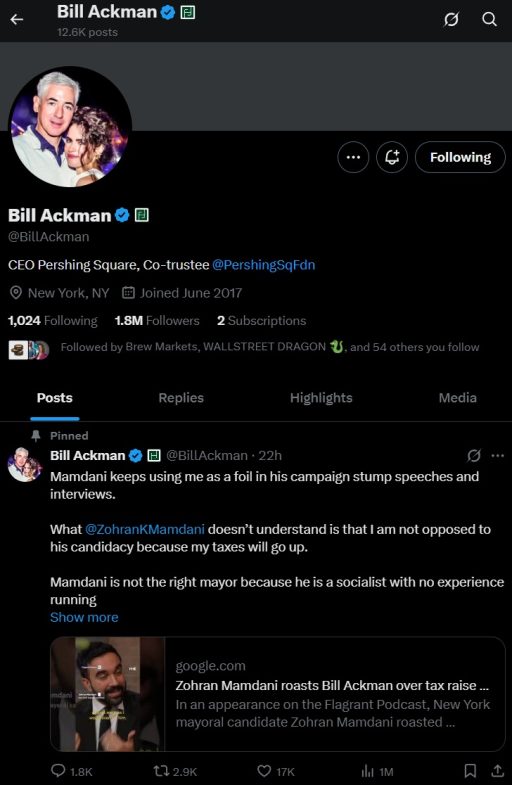
Here, Bill is discussing about the NYC mayoral race in 2025, and has been promoting the same anti-Mamdani message for about a month. In fact, his hedge fund friend named Daniel Loeb has also been promoting the same anti-Mamdani message for about a month. Coincidence? They’re both billionaires?
Let’s get real: what type of novel data will this be providing to a state-of-the-art LLM developed by the top AI researchers at OpenAI or Anthropic? What fog is this dissipating and is it just a landscape of political biases and group think?
Now, let’s move onto Reddit. Here is an example post by a user in the subred r/investing that does a technical / engineering-level deep dive into the lithography process at Intel and why it’s behind competitors (a short thesis).

The post continues on for two more pages of insightful engineering-level analysis, fleshing out a very good short thesis. This person is likely an engineer who has worked at actually manufacturing chips – maybe perhaps even at Intel. From an investment perspective, this material is gold – where else on the Internet can I find content by an anonymous user who may be sharing insider information or at the very least, incredibly helpful details about the chip manufacturing process at Intel?
By the way, if you had followed the short advice of this engineer 5 years ago, you would be up 55% cumulatively or 17% annualized from the lows of INTC this year.
Conclusion
I can go on and discuss more about the financial metrics and so forth, but at the end of the day, they have limited value when the bottleneck of AI intelligence will be in datasets like Reddit which is unique – it represents the DNA of human thought and provides creativity and ingenuity without the facade of Internet popularity and biased ranking algorithms affecting it.
This why RDDT will be invaluable to LLMs, and the principal reason why I believe it will re-rated upwards once this becomes a consensus view.

Leave a comment