
The AI industry is caught in a fundamental contradiction: the exponential growth in computational demand, driven by larger models and datasets, is physically unsustainable within the current paradigm of centralized datacenters built on locally-constrained monolithic GPUs. CMOS-based silicon chips, even advanced chiplet GPUs, are hitting immutable thermal and power density walls.
The solution to this foundational problem is not a direct replacement for CMOS remains elusive as efforts in quantum computing and photonics have yet to bear any viable near-term commercial solution. A radical architectural shift – one I am calling distributed AI computing – is needed that abandons the quest to pack ever more compute into a single facility. Instead, it disperses AI training and inference workloads across a network of specialized, smaller data centers located proximate to abundant, low-cost power sources, interconnected by a high-performance fiber optic backbone.
This transforms the physical limitation from a bottleneck into a design principle, and pushes off the staggering research efforts in order to develop frontier technologies like quantum computing or photonics that are needed to supersede thermal limitations of CMOS-based GPUs.
The Inescapable Logic: From CMOS to Constellation
The drive toward distributed computing is not a matter of preference but of physics.
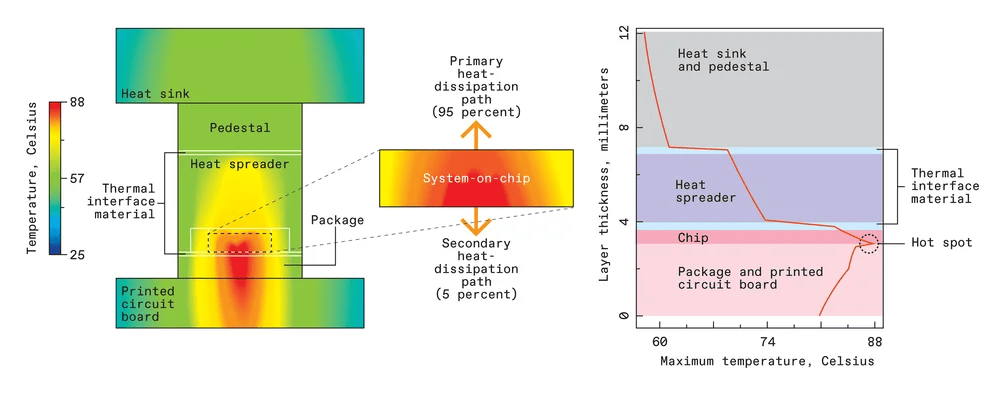
The logic chain is as follows:
- The CMOS Scaling Limit: For decades, Moore’s Law delivered exponential growth in transistor density. This era is over. As transistor features approach atomic scales, quantum effects and astronomical leakage current make further density gains marginal and prohibitively expensive. We can no longer rely on smaller, faster, cheaper chips to meet compute demand.
- The Thermal Wall: Even if we could pack more transistors, we cannot cool them. The power density of modern AI chips (CPUs, GPUs, ASICs) has reached levels comparable to a rocket nozzle. The heat generated in a concentrated space cannot be dissipated efficiently enough with existing cooling technologies, leading to thermal throttling where chips must slow down to avoid melting. Liquid cooling from providers like $VRT is not sufficient, and the next step up into LN2 cooling is simply infeasible at scale. This creates a direct trade-off: more computational power in a given space generates more heat than can be removed, imposing a hard ceiling on the performance of a single data center rack, room, and by extension, facility.
- The Exponential Demand of AI: Against this backdrop of physical limits, the computational requirements for state-of-the-art AI models are growing at a rate far exceeding Moore’s Law (some estimates suggest a 10x increase per year). Training a single frontier model now requires tens of thousands of high-wattage GPUs running continuously for months. The convergence of flat-lining chip efficiency and skyrocketing demand creates an unsustainable cost and energy curve.

The Resolution: The only viable path forward is to “unpack” the compute. Instead of building a single, gigawatt-consuming data center in a location constrained by power grid capacity and cooling infrastructure, we must disaggregate the compute fabric. By distributing the AI workload across multiple geographically dispersed sites, each located where power is cheap, abundant, and often green (e.g., hydroelectric dams, commercial nuclear reactors), we bypass the thermal and power grid limitations of a single location. The “supercomputer” is no longer a building; it is a constellation of facilities networked together.
Case Study: Microsoft’s Project “Olympus” – a Blueprint for the Future
Microsoft is not just theorizing about this model; it is actively building it. Their strategy, as detailed in this Semianalysis article, provides a concrete blueprint for distributed AI computing. This monumental project involves constructing a distributed cluster like the one shown below (running on 5GW of power) connecting 3 multi-regional datacenters in Wisconsin, North Carolina, and Texas – sites where power is cheap and plentiful.
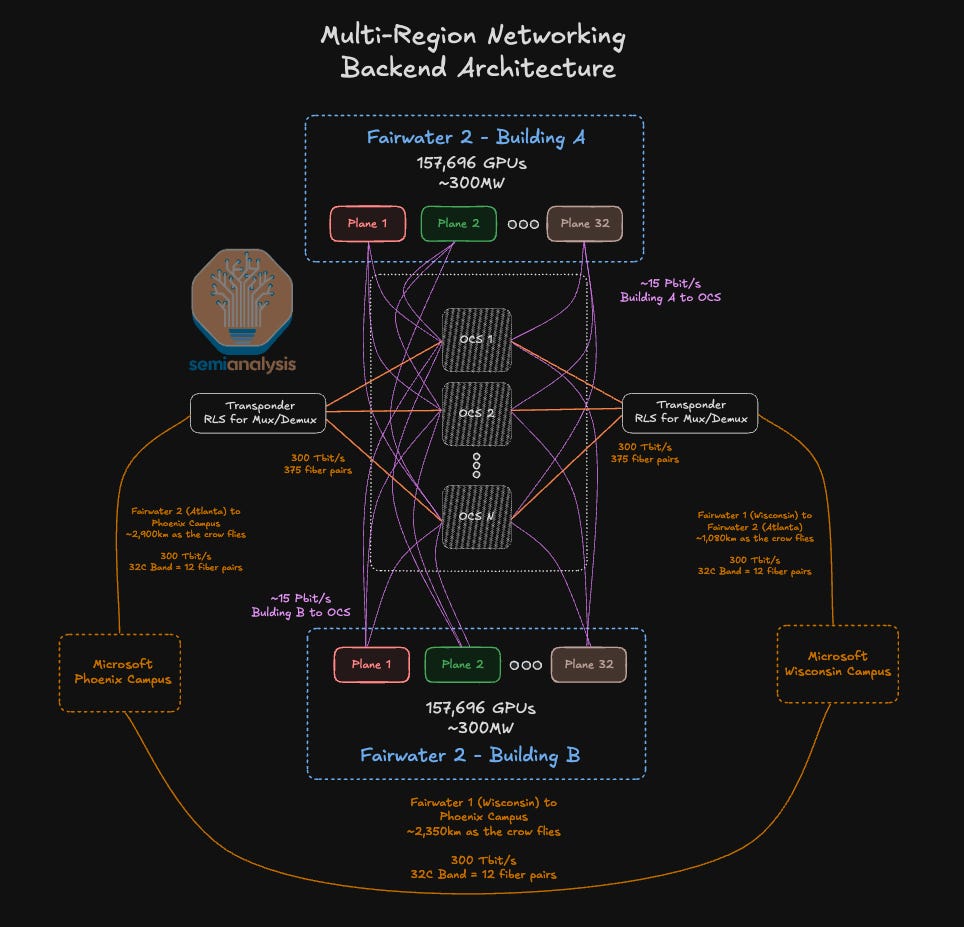
This is a canonical example of the distributed AI computing model in action. Let’s break down its components:
- The Power Source: The Texas data center, for example, has direct partnership for local renewable energy from ENGIE with a mix of wind and solar energy. This directly addresses the power scarcity and cost problem. Other future sites could be developed near commercial nuclear power plants. Nuclear provides a massive, constant, and carbon-free baseload power source, insulating the AI operations from grid instability and volatile energy markets. It is a prime example of moving compute to the power, rather than trying to bring ever more power to the compute.
- The Scale and Design: Each facility is designed as a “Gigafarm,” a single, massive campus dedicated solely to AI. This is a step beyond traditional data centers, representing a specialized asset class built from the ground up for the unique demands of AI workloads. It acknowledges that AI compute is becoming the primary function of the cloud, requiring its own infrastructure.
- The Network Backbone: While the article focuses on the power and compute, the implicit, critical component is the high-bandwidth, low-latency fiber optic network that will connect all three campuses. This is the nervous system that allows this distributed facility to function as a single, logical compute resource with other Microsoft data centers. Intensive training jobs can be split across locations, with model weights synchronized over this network in near-real-time.
- The Strategic Implication: Microsoft’s move demonstrates a fundamental strategic pivot. They are conceding that winning in AI is not just about having the best algorithms, but about securing a sustainable and scalable physical compute foundation. By locking in long-term, cheap power and building dedicated AI factories, they are creating a structural cost and capability advantage that will be difficult for competitors relying on legacy, power-constrained data center designs to match.
Investment Implications: the AI Model becomes Geographically Distributed
The paradoxical insight that AI’s growth is constrained by the physics of its own hardware leads inexorably to the investment narrative of Distributed AI Computing. The winners in the next phase of AI will not necessarily be the ones with the best LLM or even LWM (large world model) architecture, but those who control the most efficient and scalable physical compute fabric.
This creates a compelling thematic opportunity across several layers:
- Infrastructure Providers: Companies like Microsoft that are building these next-generation, power-proximal AI factories.
- Networking & Interconnect: Firms enabling the high-speed fiber and switching technology that forms the “central nervous system” of this distributed brain. Photonics will become critical with the optical amplifier market expected to benefit significantly from this architectural shift.
- Specialized Components: Companies providing advanced liquid cooling, high-density power delivery, and other technologies necessary to maximize efficiency within each node of the network.

The era of the monolithic data center is ending. The future of AI compute is a distributed, networked constellation, and the foundational build-out for this new architecture has already begun.

Leave a comment