
Paradoxical Truth: The more capable and self-designing AI models become, the less valuable the companies that design it become; and the more valuable the companies the control the physical resources the models run on – chips, energy, land become.
A Brief History of AI
1. The Foundational Architectural Layer: The Transformer Paradigm
The publication of “Attention if All you Need” in 2017, and its introduction of “transformers” is the genesis of this AI super-cycle. Before transformers, we were handcuffed by sequential processing of recurrent neural networks and LTSMs. Transformers’ seminal contribution is attention which could be perfectly parallelized on GPUs. It was a new kind of hardware-aware architecture that turned massive data into fuel. It moved the bottleneck from computation to data and scale.
2. The Methodology Layer: The “Pre-train then Fine-tine” Paradigm
With this new transformer engine, we needed a better driving strategy. The 2018 shift – epitomized by the decoder-only GPT and encoder-only BERT – proved that self-supervised pre-training created a deep, contextual understanding of language. This reusable “world model” could then be efficiently fine-tuned for specific tasks, breaking the cycle of building a new model for every single problem.
3. The Scaling Layer: The Emergent Property of Size
We had the engine and the driver, so the next natural step was to supercharge our AI vehicle. GPT-3 was our experimental proof of the scaling laws. By aggressively increasing parameters and data, we saw “emergent abilities” – like in-context learning and reasoning – arise not from explicit programming, but from the model’s sheer complexity. This was the inflection point in the first S-curve of LLMs where we stopped just teaching models, and started observing what they could teach themselves.
4. The Interaction Layer: Alignment as a Product Feature
A powerful AI vehicle is useless if we don’t have an interface to interact with it, control it, and manage its state. The ChatGPT revolution ushered by OpenAI in late 2022 was about adding this critical UI and control layer. Through reinforcement learning with human feedback (RLHF), we moved from treating the model as a text generator to shaping it as a conversational agent. This shift from raw capability to usability, forcing us to formalize the fuzzy concept of “helpfulness” into a concrete optimization target.
5. The Accessibility Layer: The Efficiency & Open-Source Mandate
The current frontier isn’t about building a bigger engine; it’s about building a more efficient and accessible vehicle. Models like DeepSeek-R1 introduced in early 2025 represent this topmost layer – a strategic focus on performance-per-watt, long-context engineering, and a commitment to open weights. This layer is about dissolving the moat of exclusivity and empowering the ecosystem to build the next breakthrough on a foundation of state-of-the-art, efficient, and open technology.
Digression into Dynamical Systems
An LLM architecture at every layer of its evolution (at least in the 5 layers highlighted above) can be modeled as a dynamical system.
Each progressive layer represents a higher-order recursion, carrying forward the model’s state across a broader temporal and systemic boundary.
- 2017: recursion parallelized
- 2018-21: recursion internalized into weights
- 2020-22: recursion emerges as meta-learening
- 2022-23: recursion closed vs. human feedback
- 2024-25: recursion externalized into ecosystem memory
We can thus formalize LLMs as a discrete dynamical system:



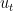


Why did I digress into this tangential mathematical model of LLMs? Because LLMs are surprisingly structured in its evolution, and each of the 5 layers has been the progressive discovery of a new state transition function g, which represents the LLM.
Coincidentally – for any fans of the Matrix – we are currently trying to the find the 6th iteration of the function g for the next LLM. Neo in the Matrix is also the 6th iteration.

From Dynamical Systems to AGI
From this peculiar perspective, the progression of LLMs can be viewed as a sequence of state transition functions, which under some metric 


My hypothesis – which can’t be proven nor disproven – is that
We are at a critical inflection point in AI evolution where we can potentially discover a state transition function g* that can self-learn, understand its limitations, recursively improve upon its intelligence, and perhaps as a stretch remove its own bugs.
This will be a profound paradigm shift in humanity’s evolution when AI can self-improve itself unsupervised, and may potentially signal the end of software as a limiting constraint of our “Matrix” – an incredible technological inversion from software to hardware which will forever redefine our existence.
When superintelligence becomes a commodity, the only thing that limits its growth and application is the physical capacity to run it.
Chips to compute it.
Energy to power it.
Land to house it.
Ironically, the final and most valuable product of the digital revolution will be the re-sovereignty of the physical world.

Leave a comment